随着数据规模的爆炸式增长和业务对实时性要求的不断提高,大数据处理架构经历了显著的演进。从早期的批处理主导,到后来的Lambda架构试图统一批流,再到以Kappa架构为代表的流处理优先,直至如今流批一体与实时数仓成为主流趋势,这一演进过程深刻反映了数据处理范式与业务需求之间的动态平衡。
一、Lambda架构:批流结合的经典范式
Lambda架构由Nathan Marz提出,其核心思想是通过并行运行批处理层和速度层(流处理层)来平衡延迟、容错和可扩展性。批处理层(如使用Hadoop MapReduce或Apache Spark)负责处理全量数据,提供高准确性的“批视图”;速度层(如使用Apache Storm或Flink)负责处理实时增量数据,提供低延迟的“实时视图”;最后通过服务层合并两者结果对外提供查询。Lambda架构的优势在于其鲁棒性——批处理层可以修正速度层因实时计算可能产生的误差。其明显缺点是复杂度高,需要维护两套独立的代码逻辑和计算管道,导致开发、运维成本巨大,且两套系统的一致性保障颇具挑战。
二、Kappa架构:流处理统一天下的简化尝试
为应对Lambda架构的复杂性,Jay Kreps提出了Kappa架构。其核心主张是:所有数据都视为流,无需独立的批处理层。系统只需一个流处理层,通过一个可重放的消息日志(如Apache Kafka)来存储所有输入数据。当需要全量重新计算或修复逻辑时,只需从头重新消费消息日志即可。Kappa架构极大地简化了系统设计,一套代码处理所有场景。Apache Flink、Apache Samza等流处理引擎的成熟,为Kappa架构提供了强有力的支撑。但其挑战在于,对消息日志的长期存储与回溯性能要求极高,并且对于某些复杂的、周期性的全量计算(如历史数据关联分析),纯流处理模式的效率可能不及批处理。
三、流批一体(Unified Batch & Streaming):架构演进的新方向
流批一体并非一个具体的架构,而是一种设计理念和框架能力,旨在让开发者能用同一套API和语义同时处理无界流数据和有界批数据。其理想状态是:开发一次,既能作为流任务低延迟运行,也能作为批任务高吞吐运行。Apache Flink是这一理念的先驱和典范,它通过其底层引擎将批数据视为一种特殊的、有界的流,实现了真正的运行时统一。Google提出的Dataflow编程模型(后由Apache Beam SDK实现)则从更高阶的API层面统一了批和流的概念,允许开发者将处理逻辑抽象为PCollection(数据集合)和Transform(转换),并可以在不同后端引擎(如Flink, Spark, Google Cloud Dataflow)上执行。流批一体解决了Lambda和Kappa架构的核心痛点,降低了开发和维护的复杂性,是当前大数据处理领域的主流方向。
四、Dataflow模型:抽象化的数据处理理论
Dataflow模型由Google在论文《The Dataflow Model》中提出,它不是一个具体系统,而是一个用于定义流批统一数据处理逻辑的理论模型。它核心解决了两个问题:
1. 数据何时被处理? 通过引入事件时间和处理时间的概念,以及窗口化(固定窗口、滑动窗口、会话窗口等)机制来组织无界数据。
2. 处理结果何时产出? 通过引入触发器和累积模式(抛弃、累积、累积并撤回)的概念,来精确控制计算结果在何时、以何种方式输出。
这个模型为流批一体提供了坚实的理论基础,使得开发者能够清晰地推理乱序、延迟数据下的计算结果准确性。Apache Beam SDK是这一模型最直接的实现。
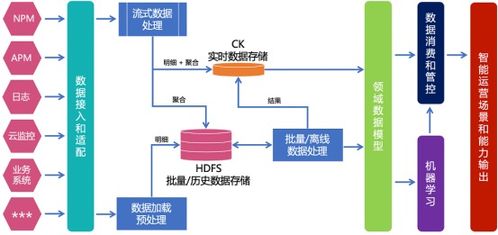
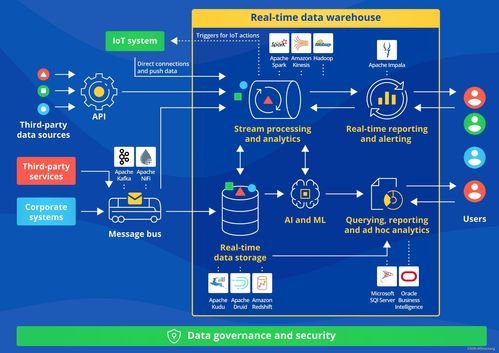
五、实时数仓:架构演进的目标与承载
实时数仓是现代数据架构的集大成者,其目标是建立一套能够同时支持低延迟实时分析(亚秒到秒级)和高效批量分析的数据仓库系统。它不再是单一的组件,而是一个融合了多种架构思想的完整解决方案:
- 数据接入层:通常基于Kafka等消息队列,实现数据的实时采集与分发。
- 数据处理层:采用流批一体引擎(如Flink)或混合架构,对数据进行实时ETL、清洗、聚合。
- 数据存储层:采用分层设计,如ODS(操作数据层)、DWD(明细层)、DWS(汇总层)、ADS(应用层)。存储选型多样化,可能包括Kafka(实时管道)、OLAP数据库(如ClickHouse、Doris、StarRocks用于即席查询)、键值存储(如HBase用于点查)以及数据湖(如Iceberg、Hudi用于全量历史数据)。
- 数据服务层:通过统一的查询引擎或API网关,对外提供一致的数据服务。
实时数仓的本质是让数据流“实时”地流入并经过处理,直接服务于数据应用,打破了传统T+1数仓的滞后性。
六、数据处理服务(Data Processing as a Service):云原生的未来
随着云计算的普及,大数据处理正在向服务化、托管化发展。各大云厂商(如AWS的EMR、Kinesis Data Analytics;阿里云的实时计算Flink版;Google Cloud Dataflow)提供了全托管的数据处理服务。用户无需关心底层集群的部署、扩缩容、监控和运维,只需专注于业务逻辑开发。这种模式将复杂的架构选择和技术运维负担转移给了云平台,让企业能更敏捷地构建实时数据能力,进一步降低了大数据技术的应用门槛。基于云原生的Serverless数据处理服务,结合流批一体与实时数仓理念,将成为企业数据基础设施的标准配置。
###
从Lambda到Kappa,再到流批一体与实时数仓,大数据处理架构的演进是一条从“分离”走向“统一”,从“复杂”走向“简洁”,从“技术驱动”走向“业务价值驱动”的清晰路径。Dataflow模型为此提供了理论基石,而云原生的数据处理服务则让这些先进架构能够以更经济、高效的方式落地。对于架构师和开发者而言,理解这些架构背后的权衡与思想,比单纯追求最新技术更为重要。选择何种架构或组合,应深度结合业务场景的数据特征、时效性要求、准确性要求、团队技能和成本约束来综合决定。